Testando o Veeam Kasten com K3s e Longhorn – Parte 1
A ideia desse artigo é mostrar passo a passo uma forma simplificada e rápida de fazer deploy do K3s com Longhorn e usar o Veeam Kasten para proteger a carga de trabalho que está sendo executada no Kubernetes. É importante frisar que todas as escolhas de design e arquitetura aqui descritas foram pensadas para ser o mais simples possível, com o objetivo bem claro de ter um ambiente funcional para testes da solução de proteção de dados para Kubernetes da Veeam. Não recomendo repetir esses passos para ambientes produtivos.
A criação do ambiente consiste em uma máquina virtual com o Ubuntu 24.04 (2 vCPU, 6GB RAM e 80GB disco), K3s 1.32, Longhorn 1.9.0 e Veeam Kasten 8.0.3 (última versão disponível). O K3s é uma versão leve do Kubernetes, ideal para testes e ambientes com poucos recursos. O deploy padrão utiliza ao menos três nós, mas aqui faremos com apenas um. O Longhorn é a parte de armazenamento distribuido para Kubernetes, ele é o responsável por armazenar os pods, réplicas e snapshots. Para armazenar os backups do Kasten, vamos utilizar um compartilhamento NFS.
Para facilitar a leitura, separei o artigo em três partes.
Parte 1 – Instalação e configuração do K3s e Longhorn (você está aqui)
Parte 2 – Instalação e configuração básica do Veeam Kasten
Parte 3 – Configuração de politicas de backup no Veeam Kasten
Agora que já apresentei o ambiente, vamos começar com a instalação de fato. Iniciamos preparando o sistema operacional, pra isso vamos desativar o swap e instalar o nfs e kubectl (sem esquecer o básico: apt update && apt upgrade -y).
swapoff -a sed -i '/ swap / s/^/#/' /etc/fstab apt install -y nfs-common snap install kubectl --classic
Vamos para a instalação e configuração do K3s, é bem simples. É importante garantir o STATUS: pass executando o comando k3s check-config. Caso não passar, valide o que faltou e corrija antes de seguir.
curl -sfL https://get.k3s.io | sh - k3s kubectl get nodes cp /etc/rancher/k3s/k3s.yaml ~/.kube/config chown $USER:$USER ~/.kube/config k3s --version k3s check-config
O Helm é o gerenciador de pacotes do Kubernetes, vamos instala-lo também. Uma unica linha e sem configurações adicionais.
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
Perfeito, vamos seguir para a instalação e configuração do Longhorn. Importante: este passo a passo foi testado apenas nas versões 1.9.0 e 1.9.2 do Longhorn.
helm repo add longhorn https://charts.longhorn.io helm repo update helm install longhorn longhorn/longhorn --namespace longhorn-system --create-namespace --version 1.9.0 kubectl get pods -n longhorn-system -w
Antes de seguir, garanta que não encontrou nenhum erro na instalação do longhorn e que todos os pods do namespace longhorn-system estão sendo executados corretamente. Se está tudo bem, então vamos configurar os CRDs de snapshot. CRD é a sigla para Custom Resource Definition e é basicamente uma forma do Kubernetes permitir que você crie novos tipos de objetos. Nesse caso, precisamos definir o que é um snapshot e como usa-lo (VolumeSnapshot, VolumeSnapshotClass e VolumeSnapshotContent são exemplos). Para isso, basta usar o kubectl apply.
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/v6.2.1/client/config/crd/snapshot.storage.k8s.io_volumesnapshotclasses.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/v6.2.1/client/config/crd/snapshot.storage.k8s.io_volumesnapshotcontents.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/v6.2.1/client/config/crd/snapshot.storage.k8s.io_volumesnapshots.yaml
Agora vamos configurar os controladores de snapshot. Eles são responsáveis por executar o snapshot de fato, ou seja, cuidam da criação, restauração e deleção dos snapshosts usando o driver CSI.
kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/v6.2.1/deploy/kubernetes/snapshot-controller/rbac-snapshot-controller.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/v6.2.1/deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml
E por fim, vamos criar duas classes: StorageClass e VolumeSnapshotClass. A primeira é como se fosse um menu de tipos de armazenamento, basicamente diz para o Kubernetes como e onde criar os volumes (PVCs). Vamos criar seguindo o modelo abaixo. Apenas uma réplica e WaitForFirstConsumer são opções pertinentes devido a configuração de um unico nó.
cat <<EOF | kubectl apply -f -
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: longhorn-single-replica
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: driver.longhorn.io
parameters:
numberOfReplicas: "1"
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
Já o VolumeSnapshotClass é uma espécie de menu de tipos de snapshot. É responsável por informar ao Kubernetes como criar e gerenciar snapshots dos volumes. Sem esse cara devidamente configurado, não poderiamos fazer snapshots e/ou restaurar usando o Kasten.
cat <<EOF | kubectl apply -f -
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: longhorn-snapshot
annotations:
k10.kasten.io/is-snapshot-class: "true"
driver: driver.longhorn.io
deletionPolicy: Delete
parameters:
type: snap
EOF
Nas configurações acima já definimos que o longhorn-single-replica será o padrão do ambiente e para evitar confusão, é melhor ajustarmos a configuração das storage class para garantir que não existam multiplas opções definidas como padrão. Nesse caso, vamos remover a anotação padrão do local-path e longhorn.
kubectl patch storageclass local-path -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
kubectl patch storageclass longhorn -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
Você deve verificar se o longhorn-single-replica (default) está com o reclaim policy definido como delete e o volume bind mode como WaitForFirstConsumer. Importante só fazer um double check se o longhorn-snapshot está apontando para o driver.longhorn.io.
kubectl get storageclass kubectl get volumesnapshotclass

Se tudo estiver correto, então vamos só configurar um ingress para podermos acessar a interface gráfica do longhorn. Obs: o Traefik é a controladora ingress instalada por padrão junto com o K3s, ele é responsável por gerenciar endereços, domínios e certificados.
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: longhorn-ingress
namespace: longhorn-system
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web
spec:
ingressClassName: traefik
rules:
- host: longhorn.caverna.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: longhorn-frontend
port:
number: 80
EOF
O acesso é realizado pelo endereço definido no host, aqui ficou como longhorn.caverna.local. Temos alguns detalhes interessantes aqui. Primeiro que certas configurações que você faz via console são aplicadas apenas para a criação dos volumes via GUI. É o caso das réplicas, onde poderiamos ter usado o comando kubectl patch -n longhorn-system setting default-replica-count –type=merge -p ‘{“value”:”1″}’, mas não surtiria o efeito desejado, por isso foi necessário criar uma nova storage class.

Outro detalhe é sobre como o longhorn trata a utilização dos volumes. Se você criar um volume de 20G e ocupar apenas 200MB, na coluna allocated vai aparecer os 20GB e se você tiver 2 réplicas, então aparecerá 40GB e por aí vai. Se ultrapassar os 52.81GB (no meu caso), o status do node muda para unschedulable e nada vai funcionar. O longhorn usa isso para reservar espaço para as réplicas, snapshot etc.
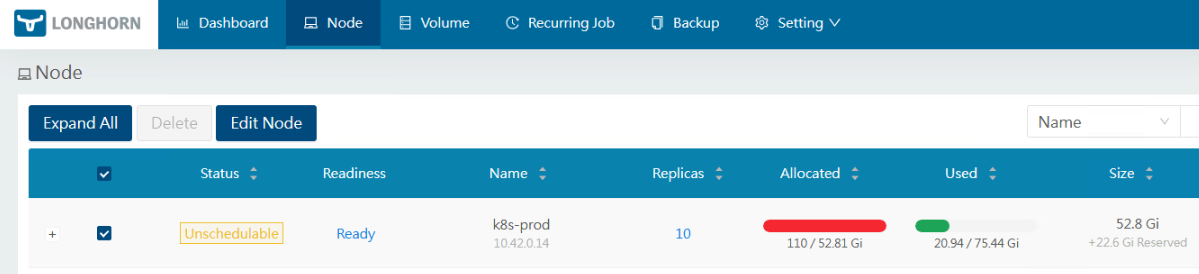
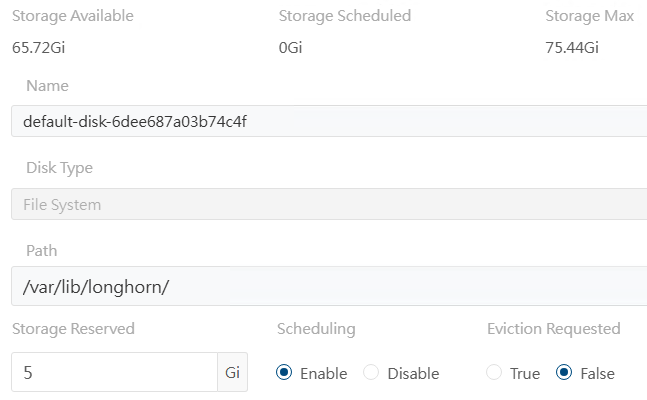
Isso é importante, mas em um ambiente produtivo provavelmente não seria um problema. Já falei, mas vou reforçar: aqui estamos tentando otimizar o ambiente para ter um laboratório funcional de Veeam Kasten com o mínimo de hardware possível e por isso vamos fazer algumas gambiarras adaptações técnicas que jamais deveriam ser feitas em ambientes produtivos. Basta clicar em edit node e disks na coluna operation e reduzir o tamanho do armazenamento reservado.
Em teoria, agora temos tudo o que precisamos para seguir com a instalação do Veeam Kasten. Na parte 2 deste artigo vamos seguir com a instalação e configurações. Até mais!